Performant Text Highlighting Plugin - advanced-mark.js
| File Size: | 458 KB |
|---|---|
| Views Total: | 1464 |
| Last Update: | |
| Publish Date: | |
| Official Website: | Go to website |
| License: | MIT |

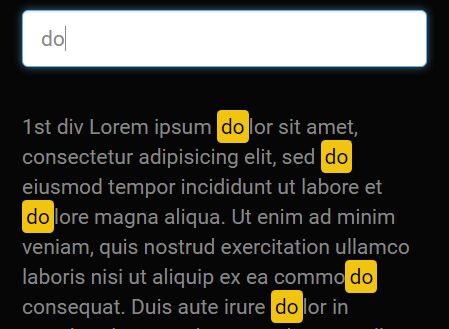
advanced-mark.js is a fast and lightweight JavaScript library for highlighting characters, words, terms, phrases, and even text ranges on web pages.
With support for virtual DOMs, advanced-mark.js can update highlights efficiently when content changes, making it easier to integrat across various platforms.
How to use it:
1. Install & download.
# NPM $ npm i advanced-mark.js
2. Import the advanced-mark.js.
// Vanilla JavaScript import Mark from '/path/to/mark.es6.js'; // jQuery import Mark from '/path/to/jquery.mark.es6.js';
<!-- Browser (Vanilla JavaScript) --> <script src="/dist/mark.js"></script> <!-- Browser (jQuery) --> <script src="/path/to/cdn/jquery.slim.min.js"></script> <script src="/dist/jquery.mark.min.js"></script>
3. The mark() method allows highlighting text by passing the terms to look for.
// Vanilla JavaScript
var instance = new Mark(selector/array/element/nodelist);
instance.mark('contentToHighlight', options);
// jQuery
$(".element").mark('contentToHighlight', options);
4. For more advanced matching, markRegExp() accepts regular expressions to target text patterns.
// Vanilla JavaScript
var instance = new Mark(selector/array/element/nodelist);
instance.markRegExp(regexHere, options);
// jQuery
$(".element").markRegExp(regexHere, options);
5. The markRanges() method highlights specific character ranges.
// Vanilla JavaScript
var instance = new Mark(selector/array/element/nodelist);
instance.markRanges([{ start: 0, length: 5 }, { start: 12, length: 16 }], options);
// jQuery
$(".element").markRanges([{ start: 0, length: 5 }, { start: 12, length: 16 }], options);
6. Use the unmark() method to clear all marks.
// Vanilla JavaScript
var instance = new Mark(selector/array/element/nodelist);
instance.unmark(options);
// jQuery
$(".element").unmark(options);
7. Style the highlighted content in your CSS.
mark {
/* your styles here */
}
8. All possible options:
const options = {
// custom mark element
element : 'mark',
// additional CSS class appended to the highlighted element
className : '',
// When it set to true, if a searching string contains several words, it splits the string by spaces into separate words and highlights individual words instead of the whole string.
// It also applies to every string in a searching array.
// When it set to 'preserveTerms', it preserved term(s) surrounding by double quotes from breaking into separate words.
// This allows highlight exact term(s) alone side with individual words.
It can be useful, when library is used to highlight searchings or in case of using a string instead of an array and there is need to keep some term(s) intact.
// It also allows highlight quoted terms no matter how many quotes it contains on each side (but not in the middle), e.g. ""term"" - marked "term", """"term" - """term.
separateWordSearch : true,
// match diacritic characters
diacritics : true,
// exclude these characters,
exclude : [],
// case sensitive or not
caseSensitive : false,
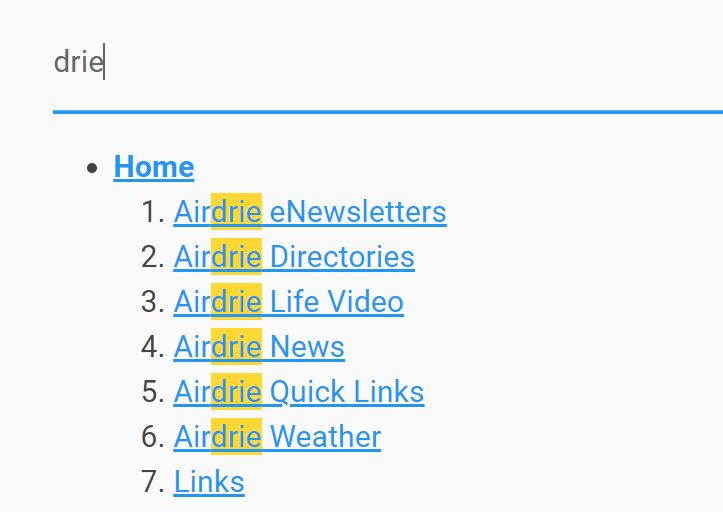
// 'partially' e.g. searching 'a' mark 'a' in words 'and', 'back', and 'visa'.
// startsWith The search is restricted by word boundaries.
// 'exactly' This option is actually forced to use an accuracy object, because the default word boundaries are white spaces and start/end of a text node content (with acrossElements option - start/end of a context).
// 'startsWith' e.g. searching 'pre' mark the whole words 'prefix', 'predict', and 'prefab'.
// 'complementary' e.g. searching 'a' mark the whole words 'and', 'back', and 'visa'.
accuracy : 'partially',
// an object with synonyms
// e.g. { 'one': '1' } - '1' is synonym for 'one' and vice versa.
// he value can be an array, e.g. { 'be': ['am', 'is', 'are'] }.
synonyms : {},
// find matches that contain soft hyphen, zero width space, zero width non-joiner and zero width joiner
ignoreJoiners : false,
// a string or an array of punctuation characters
ignorePunctuation : [],
// disabled: The characters ? and * match itself
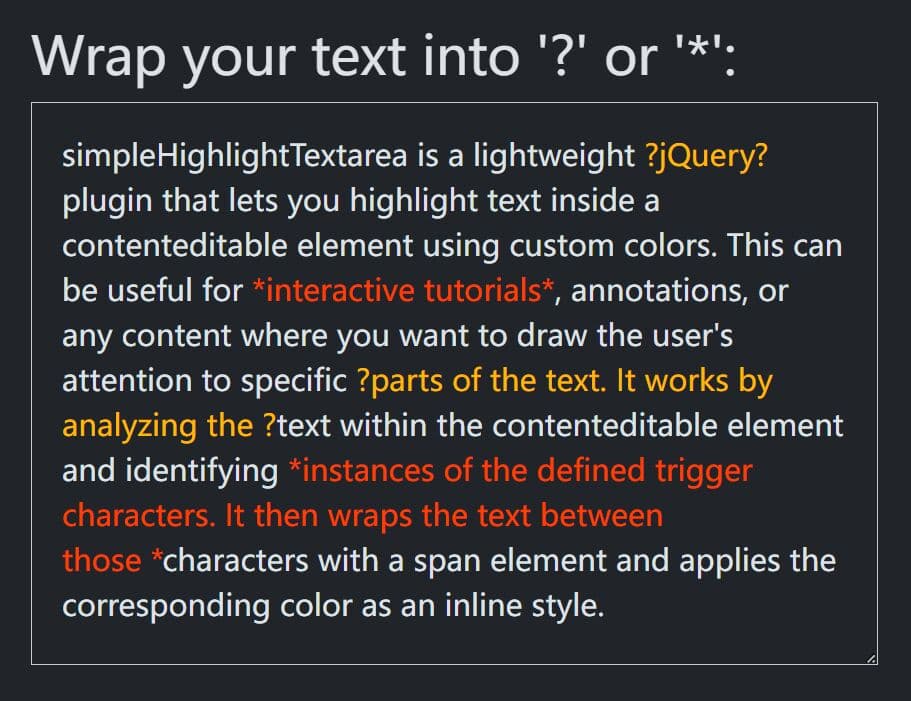
// enabled: The character ? match any non-white-space character zero or one time; The character * match any non-white-space character zero or more time.
// withSpaces: The character ? match any character zero or one time; The character * match any character zero or more time, but as few times as possible.
wildcards : 'disabled',
// search for matches across elements
acrossElements : false,
// combine a specified number of individual term patterns into one
combinePatterns : false,
// cache text nodes to improve performance
cacheTextNodes : false,
// limit matches within default HTML block elements and/or custom elements
// tagNames string[] - An array of custom HTML tag names
// extend boolean - true extends default boundary elements by the custom elements otherwise only the custom elements do have boundaries
// char string - A custom boundary character. The default is \x01.
blockElementsBoundary : false,
// mark inside shadow DOMs
shadowDOM : false,
// mark inside iframes
iframes : false,
// max time to wait for iframe(s) to load before skipping
iframesTimeout : 5000,
// callback to filter matches.
// textNode Text - The text node which includes the match or with acrossElements option can be part of the match
// term string - The current term
// matchesSoFar number - The number of all wrapped matches so far
// termMatchesSoFar number - The number of wrapped matches for the current term so far
// filterInfo object:
// match array - The result of RegExp exec() method
// matchStart boolean - indicate the start of a match AE
// execution object - The helper object for early abort:
// abort boolean - Setting it to true breaks method execution
// offset number - When 'acrossElements: false': the absolute start index of a text node in joined context. When 'acrossElements: true': the sum of the lengths of separated spaces or boundary strings that were added to the composite string so far.
filter : (textNode, term, marksSoFar, termMarksSoFar, filterInfo) => {
return true; // must return either true or false
},
// callback for each marked element
// markElement HTMLElement - The marked DOM element
// eachInfo object:
// match array - The result of RegExp exec() method
// matchStart boolean - Indicate the start of a match AE
// count number - The number of wrapped matches so far
each : (markElement, eachInfo) => {},
// callback on finish
// totalMarks number - The total number of marked elements
// totalMatches number - The total number of matches
// termStats object - An object containing an individual term's matches count
done : (totalMarks, totalMatches, termStats) => {},
// callbackwhen a term has no match at all
noMatch : (term) => {},
// debug mode
debug : false,
log : window.console,
// options for the markRegExp() method
// mark nesting/overlapping capturing groups
wrapAllRanges : undefined,
filter : (textNode, matchString, matchesSoFar, filterInfo) => {
return true; // must return either true or false
},
noMatch : (regex) => {},
// options for the markRanges() method
// mark nesting/overlapping capturing groups
wrapAllRanges : undefined,
// whether to mark ranges of lines instead of ranges of texts
markLines: undefined,
filter : (textNode, range, matchingString, index) => {
return true;
},
noMatch : (range) => {},
};
Alternatives:
Changelog:
v3.0.0 (04/17/2026)
- Combine pattern become default
- Added requirement for g flag in markRegExp() API when not using acrossElements option.
- Dropped support to highlight RegExp groups without d flag.
- Removed RegExpCreator module from the npm package.
- Added support for CSS Custom Highlight API.
- Added the ability to break an execution on the 'each' callback.
- Dropped support of very older browsers.
v2.7.1 (04/09/2026)
- Fixed the 'filter' callback 'matchesSoFar' counter (3 parameter) that affected the mark() method with the 'combinePatterns' option.
v2.7.0 (08/01/2025)
- Updated dependencies
v2.6.1 (04/08/2025)
- Updated dependencies
v2.6.0 (05/05/2024)
- Added ability to mark inside iframes in shadow DOM.
- Changed the way to truck iframes states (dropped using attribute).
- Added ability to use HTMLCollection (returned by 'getElementsByClassName()' and 'getElementsByTagName()').
v2.5.0 (04/05/2024)
- Added ability to select iframe elements when using non-jQuery libraries and iframe elements are dynamically created by javascript.
- Fixed multiple wrapping of highlighted text in mark elements that can occur on some conditions with iframes option (page contains several iframes and selecting several contexts). Previous 2.x.x versions correctly handle only one context.
- Fixed bug that is related to old browsers in DOMIterator class, e.g. IE11.
v2.4.2 (03/27/2024)
- Fixed bug that occurs in markRanges() API then an array of ranges have a single item and a range start property is zero.
2023-11-20
- Fixed infinite loop that can occur with ignoreGroups option in markRegExp() API with the conditional main group.
- Fixed missing window object of the Node interface (causes an exception in virtual DOM environments when context is an array of elements).
2023-11-15
- Fixed handling escaped wildcards characters (backslashes were stripped from searching string, e.g. 'C:\\\\*' resulted in 'C:\\*' and is treated as escape '*', not a wildcard)
2023-11-15
- Fixed handling escaped wildcards characters (backslashes were stripped from searching string, e.g. 'C:\\\\*' resulted in 'C:\\*' and is treated as escape '*', not a wildcard)
- Fixed breaking UTF-16 surrogate pairs and continues pairs of backslashes by joiners/punctuation
- Slightly reduce a code size
2023-11-09
- refactoring to reduce a code size
2023-11-06
- Added preserveTerms value for separateWordSearch option that allows highlight exact term(s) alone side with separate word(s).
- Added 'startsWith' value for accuracy option that allows highlight whole word(s) just typing the start of it(s). It also works with preserveTerms.
This awesome jQuery plugin is developed by angezid. For more Advanced Usages, please check the demo page or visit the official website.